 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY3D-Bench: Generation of 3D Assets
Feb 03, 2026While recent advances in neural representations and generative models have revolutionized 3D content creation, the field remains constrained by significant data processing bottlenecks. To address this, we introduce HY3D-Bench, an open-source ecosystem designed to establish a unified, high-quality foundation for 3D generation. Our contributions are threefold: (1) We curate a library of 250k high-fidelity 3D objects distilled from large-scale repositories, employing a rigorous pipeline to deliver training-ready artifacts, including watertight meshes and multi-view renderings; (2) We introduce structured part-level decomposition, providing the granularity essential for fine-grained perception and controllable editing; and (3) We bridge real-world distribution gaps via a scalable AIGC synthesis pipeline, contributing 125k synthetic assets to enhance diversity in long-tail categories. Validated empirically through the training of Hunyuan3D-2.1-Small, HY3D-Bench democratizes access to robust data resources, aiming to catalyze innovation across 3D perception, robotics, and digital content creation.
A Comparative Evaluation of Large Vision-Language Models for 2D Object Detection under SOTIF Conditions
Jan 30, 2026Reliable environmental perception remains one of the main obstacles for safe operation of automated vehicles. Safety of the Intended Functionality (SOTIF) concerns safety risks from perception insufficiencies, particularly under adverse conditions where conventional detectors often falter. While Large Vision-Language Models (LVLMs) demonstrate promising semantic reasoning, their quantitative effectiveness for safety-critical 2D object detection is underexplored. This paper presents a systematic evaluation of ten representative LVLMs using the PeSOTIF dataset, a benchmark specifically curated for long-tail traffic scenarios and environmental degradations. Performance is quantitatively compared against the classical perception approach, a YOLO-based detector. Experimental results reveal a critical trade-off: top-performing LVLMs (e.g., Gemini 3, Doubao) surpass the YOLO baseline in recall by over 25% in complex natural scenarios, exhibiting superior robustness to visual degradation. Conversely, the baseline retains an advantage in geometric precision for synthetic perturbations. These findings highlight the complementary strengths of semantic reasoning versus geometric regression, supporting the use of LVLMs as high-level safety validators in SOTIF-oriented automated driving systems.
FinMR: A Knowledge-Intensive Multimodal Benchmark for Advanced Financial Reasoning
Oct 09, 2025Multimodal Large Language Models (MLLMs) have made substantial progress in recent years. However, their rigorous evaluation within specialized domains like finance is hindered by the absence of datasets characterized by professional-level knowledge intensity, detailed annotations, and advanced reasoning complexity. To address this critical gap, we introduce FinMR, a high-quality, knowledge-intensive multimodal dataset explicitly designed to evaluate expert-level financial reasoning capabilities at a professional analyst's standard. FinMR comprises over 3,200 meticulously curated and expertly annotated question-answer pairs across 15 diverse financial topics, ensuring broad domain diversity and integrating sophisticated mathematical reasoning, advanced financial knowledge, and nuanced visual interpretation tasks across multiple image types. Through comprehensive benchmarking with leading closed-source and open-source MLLMs, we highlight significant performance disparities between these models and professional financial analysts, uncovering key areas for model advancement, such as precise image analysis, accurate application of complex financial formulas, and deeper contextual financial understanding. By providing richly varied visual content and thorough explanatory annotations, FinMR establishes itself as an essential benchmark tool for assessing and advancing multimodal financial reasoning toward professional analyst-level competence.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
X-Part: high fidelity and structure coherent shape decomposition
Sep 10, 2025



Generating 3D shapes at part level is pivotal for downstream applications such as mesh retopology, UV mapping, and 3D printing. However, existing part-based generation methods often lack sufficient controllability and suffer from poor semantically meaningful decomposition. To this end, we introduce X-Part, a controllable generative model designed to decompose a holistic 3D object into semantically meaningful and structurally coherent parts with high geometric fidelity. X-Part exploits the bounding box as prompts for the part generation and injects point-wise semantic features for meaningful decomposition. Furthermore, we design an editable pipeline for interactive part generation. Extensive experimental results show that X-Part achieves state-of-the-art performance in part-level shape generation. This work establishes a new paradigm for creating production-ready, editable, and structurally sound 3D assets. Codes will be released for public research.
Digital Twin-Empowered Voltage Control for Power Systems
Dec 09, 2024


Emerging digital twin technology has the potential to revolutionize voltage control in power systems. However, the state-of-the-art digital twin method suffers from low computational and sampling efficiency, which hinders its applications. To address this issue, we propose a Gumbel-Consistency Digital Twin (GC-DT) method that enhances voltage control with improved computational and sampling efficiency. First, the proposed method incorporates a Gumbel-based strategy improvement that leverages the Gumbel-top trick to enhance non-repetitive sampling actions and reduce the reliance on Monte Carlo Tree Search simulations, thereby improving computational efficiency. Second, a consistency loss function aligns predicted hidden states with actual hidden states in the latent space, which increases both prediction accuracy and sampling efficiency. Experiments on IEEE 123-bus, 34-bus, and 13-bus systems demonstrate that the proposed GC-DT outperforms the state-of-the-art DT method in both computational and sampling efficiency.
A Conversational Brain-Artificial Intelligence Interface
Feb 22, 2024



We introduce Brain-Artificial Intelligence Interfaces (BAIs) as a new class of Brain-Computer Interfaces (BCIs). Unlike conventional BCIs, which rely on intact cognitive capabilities, BAIs leverage the power of artificial intelligence to replace parts of the neuro-cognitive processing pipeline. BAIs allow users to accomplish complex tasks by providing high-level intentions, while a pre-trained AI agent determines low-level details. This approach enlarges the target audience of BCIs to individuals with cognitive impairments, a population often excluded from the benefits of conventional BCIs. We present the general concept of BAIs and illustrate the potential of this new approach with a Conversational BAI based on EEG. In particular, we show in an experiment with simulated phone conversations that the Conversational BAI enables complex communication without the need to generate language. Our work thus demonstrates, for the first time, the ability of a speech neuroprosthesis to enable fluent communication in realistic scenarios with non-invasive technologies.
Prototype-Aware Heterogeneous Task for Point Cloud Completion
Sep 05, 2022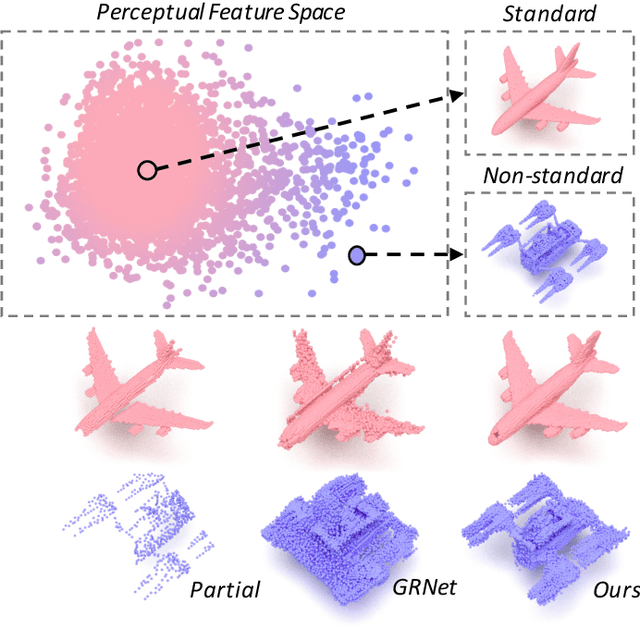
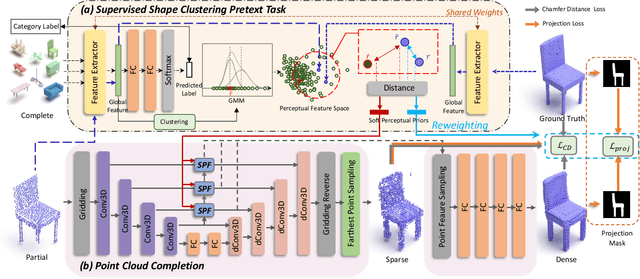

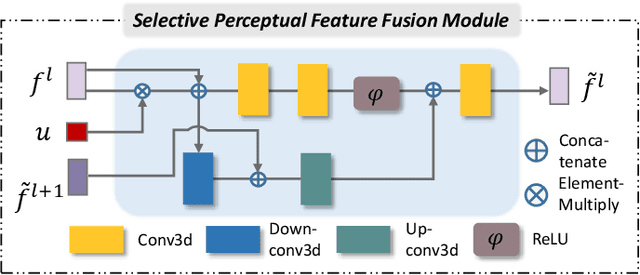
Point cloud completion, which aims at recovering original shape information from partial point clouds, has attracted attention on 3D vision community. Existing methods usually succeed in completion for standard shape, while failing to generate local details of point clouds for some non-standard shapes. To achieve desirable local details, guidance from global shape information is of critical importance. In this work, we design an effective way to distinguish standard/non-standard shapes with the help of intra-class shape prototypical representation, which can be calculated by the proposed supervised shape clustering pretext task, resulting in a heterogeneous component w.r.t completion network. The representative prototype, defined as feature centroid of shape categories, can provide global shape guidance, which is referred to as soft-perceptual prior, to inject into downstream completion network by the desired selective perceptual feature fusion module in a multi-scale manner. Moreover, for effective training, we consider difficulty-based sampling strategy to encourage the network to pay more attention to some partial point clouds with fewer geometric information. Experimental results show that our method outperforms other state-of-the-art methods and has strong ability on completing complex geometric shapes.
Compound Figure Separation of Biomedical Images: Mining Large Datasets for Self-supervised Learning
Aug 30, 2022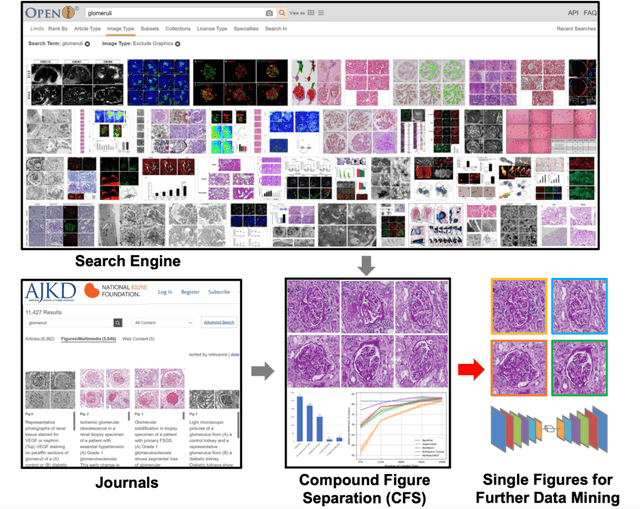
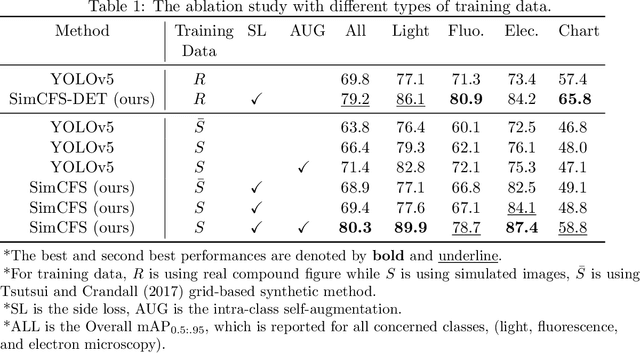
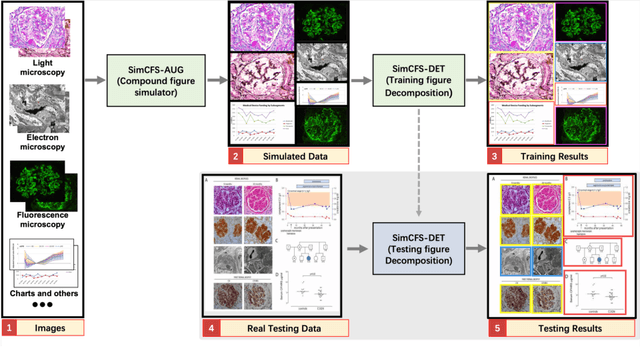
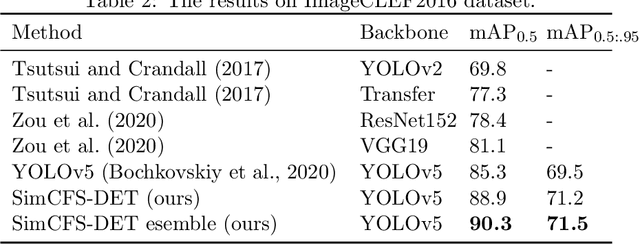
With the rapid development of self-supervised learning (e.g., contrastive learning), the importance of having large-scale images (even without annotations) for training a more generalizable AI model has been widely recognized in medical image analysis. However, collecting large-scale task-specific unannotated data at scale can be challenging for individual labs. Existing online resources, such as digital books, publications, and search engines, provide a new resource for obtaining large-scale images. However, published images in healthcare (e.g., radiology and pathology) consist of a considerable amount of compound figures with subplots. In order to extract and separate compound figures into usable individual images for downstream learning, we propose a simple compound figure separation (SimCFS) framework without using the traditionally required detection bounding box annotations, with a new loss function and a hard case simulation. Our technical contribution is four-fold: (1) we introduce a simulation-based training framework that minimizes the need for resource extensive bounding box annotations; (2) we propose a new side loss that is optimized for compound figure separation; (3) we propose an intra-class image augmentation method to simulate hard cases; and (4) to the best of our knowledge, this is the first study that evaluates the efficacy of leveraging self-supervised learning with compound image separation. From the results, the proposed SimCFS achieved state-of-the-art performance on the ImageCLEF 2016 Compound Figure Separation Database. The pretrained self-supervised learning model using large-scale mined figures improved the accuracy of downstream image classification tasks with a contrastive learning algorithm. The source code of SimCFS is made publicly available at https://github.com/hrlblab/ImageSeperation.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://www.melba-journal.org/papers/2022:025.html. arXiv admin note: substantial text overlap with arXiv:2107.08650
Holistic Fine-grained GGS Characterization: From Detection to Unbalanced Classification
Jan 31, 2022



Recent studies have demonstrated the diagnostic and prognostic values of global glomerulosclerosis (GGS) in IgA nephropathy, aging, and end-stage renal disease. However, the fine-grained quantitative analysis of multiple GGS subtypes (e.g., obsolescent, solidified, and disappearing glomerulosclerosis) is typically a resource extensive manual process. Very few automatic methods, if any, have been developed to bridge this gap for such analytics. In this paper, we present a holistic pipeline to quantify GGS (with both detection and classification) from a whole slide image in a fully automatic manner. In addition, we conduct the fine-grained classification for the sub-types of GGS. Our study releases the open-source quantitative analytical tool for fine-grained GGS characterization while tackling the technical challenges in unbalanced classification and integrating detection and classification.